
はじめに
「達人に学ぶDB設計入門」を読んでDB設計で大切だと感じたポイントを自分なりにまとめます。
DB設計をあまり担当したことがない方でも概要を掴めるように書いていきたいと思います。
今回取り扱うDBの種類
商用で利用されるデータベースは下記のように何種類かありますが、今回はリレーショナルデータベース(Relational Database: RDB)に絞ってまとめます。
- リレーショナルデータベース(Relational Database: RDB)
- オブジェクト指向データベース(Object Oriented Database: OODB)
- XMLデータベース(XML Database: XMLDB)
- キー・バリュー型ストア(Key-Value Store: KVS)
- 階層型データベース(Hierarchical Database)
また、リレーショナルデータベースでもDBMSはいくつか種類がありますが、どのDBMSでも基本的には設計の方法は影響を受けないため、RDS全体として汎用的に使える内容をまとめます。
なぜDB設計が重要か?
設計は、システム開発の工程(要件定義⇒設計⇒開発⇒テスト)の中の一つです。
DB設計はさらにその設計工程の中のサブ工程の一つです。
それでもDB設計が重要な理由は以下の2つです。
- システム内のデータの大半はDBに保存されるため、データ設計≒データベース設計であるため
- 近年ソフトウェア開発では、データ中心アプローチ(Data Oriented Approach: DOA)の考え方が主流であり、最初にデータがあり、その上で処理(プログラム)ができるため
3層スキーマ
DB設計では、データ構造やフォーマットという意味である「スキーマ」と呼ばれる概念が重要です。
スキーマは3つのレベルに分けられます。
- 外部スキーマ:テーブルやビュー(画面やデータ)←ユーザー
- 概念スキーマ:テーブル定義(データ要素やデータ同士の関係)←開発者
- 内部スキーマ:データの物理的配置(テーブルやインデックスの物理的定義)←DBMS
概念スキーマの設計を「論理設計」、内部スキーマの設計を「物理設計」と呼びます。
論理設計
概念スキーマを定義する設計を論理設計と呼びます。
重要なことは「論理設計は物理設計に先立つ」ということです。
論理設計は、物理層の制約(DBサーバのCPUパワーやストレージ、DBMSで使用できるデータ型やSQL)に囚われません。
論理設計のステップ
論理設計は下記の流れで行われますが、今回はその中でも重要な「正規化」の概念について中心に記載します。
- エンティティの抽出
- エンティティの定義
- 正規化
- ER図の作成
正規化
正規化の具体的な手順をまとめる前に、正規化のポイントと必要性を記載します。
正規化のポイントと必要性
正規化のポイントは下記3点です。
- 正規化とはデータの冗長性を排除し、データ更新時の不都合を排除するために行う
- 正規化を行うポイントはカラム同士の従属性
- 正規化は、無損失分解(情報を保存する)なので、結合で元のテーブルに復元可能だが、パフォーマンスが悪化する
基本的に、第三正規化までは原則として行うことが基本方針として記載されているため、今回は第三正規化までの手順をまとめていきます。
第一正規化
「一つのセルの中に一つの値しか含まないこと」
第二正規化
「部分関数従属をなくし、完全関数従属のみのテーブルを作ること」
部分関数従属とは、主キーの一部の列に対して従属する列があることです。
下記の例では、2つの主キー「学校コード」「生徒ID」がありますが、「学校名」は「学校コード」にのみ従属しています。
完全関数従属ではない状態
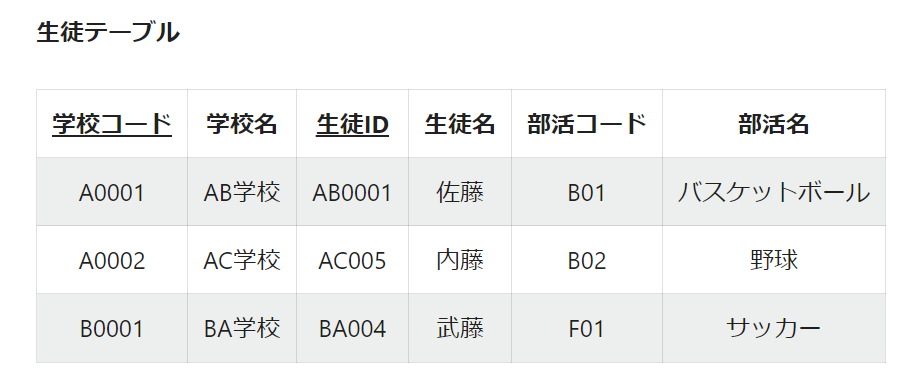
これを、完全関数従属(各カラムが主キーを構成するすべての列に従属性があること)のみのテーブルになるように2つに分割します。
こうすることで、生徒の情報がわからない学校でも登録できますし、レコードによって学校コードと学校名の対応がずれるといったこともなくなります。
完全関数従属な状態
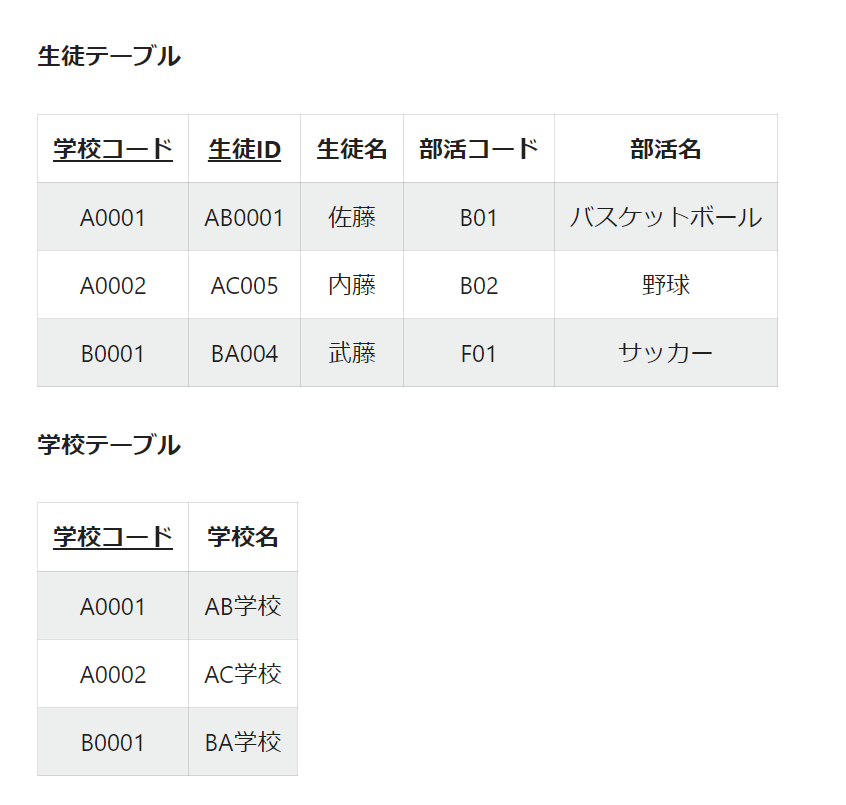 基本的には、異なるレベルのエンティティはテーブルとしても分割すべきという見方です。
基本的には、異なるレベルのエンティティはテーブルとしても分割すべきという見方です。
第三正規化
「推移的関数従属をなくすこと」
推移的関数従属とは、下表でいう「学校コード、生徒ID」⇒「部活コード」⇒「部活名」といった二段階の関数従属があることです。
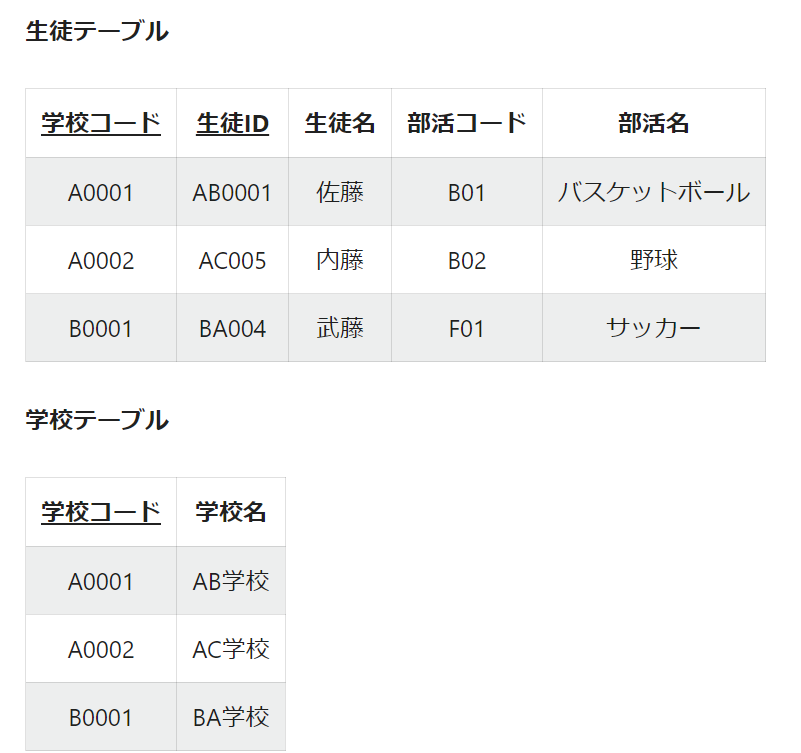
推移的関数従属がある場合、生徒が一人もいない部活を登録できないといった弊害が生まれます。
このようなデータ登録時の不都合を解消するためには、第二正規化と同じようにテーブルを分割することが必要です。
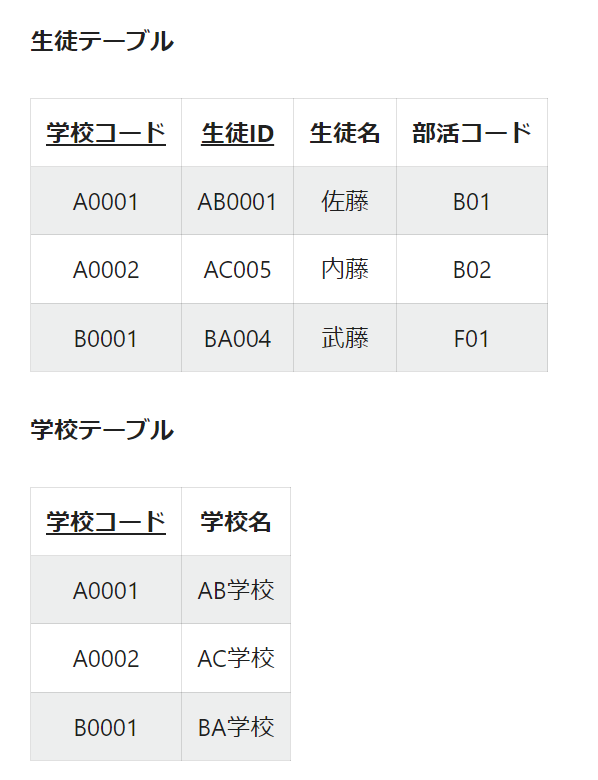

物理設計
- テーブル定義
- インデックス定義
- ハードウェアのサイジング
- ストレージの冗長構成決定
- ファイルの物理配置決定
インデックス設計
インデックスとは、キーとそれに結びつく情報(データへのポインタ)の形式の配列(x, α)のことです。
SQLチューニングのの手段としてポピュラーであり、SQL文はインデックスをたどることでテーブルの特定レコードにアクセスすることが可能です。
インデックスの特徴
インデックスの特徴は下記の3点です。
- アプリケーションに影響を与えない(データベース側にインデックスを作成するだけ)
- テーブルデータに影響を与えない(インデックス作成によりデータが変更されることはない)
- 性能改善の影響が大きい
インデックスを作成するべき列はどこか?
インデックスは闇雲に作成すればいいわけではなく、いくつかの指針があります。
- 大規模なテーブルに対して作成する(1万件以下のデータ量ではインデックスの効果がない)
- カーディナリティ(特定の列の値がどのぐらいの種類の多さを持つか)の高い列に作成する
- SQL文でWHERE句の選択条件や結合条件に使用される列に作成する
ストレージの冗長構成
RAIDは少なくともRAID5で構成する。お金に余裕があればRAID10。RAID0は論外。
最後に
「達人に学ぶDB設計入門」はDB設計初心者から経験者までポイントを掴んで設計を学べる良書だと感じました。
改めてDB設計を座学で学びたいという方は読んでみることをお勧めします。
参考文献
達人に学ぶDB設計 徹底指南書 初級者で終わりたくないあなたへ
|
|
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/2c61b132.706604e6.2c61b133.716b67a4/?me_id=1278256&item_id=11631752&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Frakutenkobo-ebooks%2Fcabinet%2F0888%2F2000000200888.jpg%3F_ex%3D240x240&s=240x240&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")




コメント